| © APSIS GmbH |
In diesem Kapitel werden einige grundlegende Gedanken zum Thema Programmieren vermittelt. Der eigentliche Sprachunterricht fängt erst im nächsten Kapitel an. Daher kann dieser Abschnitt beim ersten Lesen überflogen und erst später ausführlich betrachtet werden.
Worin liegt der große Vorteil von elektronischen Rechenanlagen gegenüber einem denkenden Menschen? Die Antwort auf diese Frage hat im Wesentlichen zwei Aspekte.
Der Erste ist die Geschwindigkeit: Computer sind - zumindest in einigen Bereichen - schneller als Menschen. Sie führen ihre Rechenoperationen mit einer um mehrere Größenordnungen höheren Geschwindigkeit aus, als wozu der am schnellsten denkende Mensch jemals fähig sein wird. Dieser Vorteil liegt im Unterschied der physikalischen Funktionsweise des menschlichen Gehirns und der Elektronik.
Dies war der historisch erste Grund für die Verwendung von Rechnern. Selbst die primitivsten Computer der ersten Generation berechneten mathematische Aufgaben, lösten Differenzialgleichungen und Probleme aus Physik und Technik deutlich schneller als ihre Programmierer. Selbst die mühsame Programmierung dieser Aufgaben auf Maschinensprache war es wert, den Geschwindigkeitsvorteil zu erlangen.
Auch die älteste, weit verbreitete höhere Programmiersprache, die - im Gegensatz zu den maschinenorientierten Programmiersprachen - mehr am Menschen als an der Maschine orientiert war, nämlich Fortran (Abkürzung für formula translation, auf deutsch etwa Formelübersetzung), war für den Zweck entworfen, mathematisch formulierte Aufgaben in den Rechner einzugeben. Der Computer forderte dann die Eingabedaten an, rechnete eine Weile und gab die Ergebnisse als Ausgabedaten aus. Die langsamste Stelle dieses Prozesses war die Ein- und Ausgabe der Daten, die aus diesem Grund typischerweise - im Vergleich zu den Rechenoperationen, die mit ihnen ausgeführt worden sind - wenige waren. Man spricht in diesem Fall von rechenintensiven Programmen. Die technisch-wissenschaftliche Datenverarbeitung arbeitet mit solchen, und in diesem Bereich wird Fortran (wie manche meinen, leider) auch heute noch oft benutzt.
Später ermöglichte die Entwicklung der Technik die interne Speicherung von Daten, die auf diese Weise nicht immer über den Flaschenhals der Ein- und Ausgabe laufen mussten. Auf magnetbeschichteten Speichern (wie Bänder, Trommel, später Platten) konnten - nachdem sie eingelesen wurden - immer mehr Daten zwischengespeichert werden, die dann für spätere Verarbeitung zur Verfügung standen. Die Programme konnten die (notwendigerweise eingeschränkte Menge von) Ausgabedaten (z.B. den Druck von Rechnungen) aus einer wesentlich größeren Menge von gespeicherten Daten (z.B. alle Kunden eines Unternehmens) errechnen.
Auf diese Weise wurde der zweite Vorteil der elektronischen Datenverarbeitung der EDV offensichtlich: die Fähigkeit, große Datenmengen zu bearbeiten. Mit menschlichen Anstrengungen ist es nur sehr schwer möglich, den Berg von Daten zu verwalten, der in einem (heutzutage schon kleinen) Computer vorhanden ist.
Die zweite, auch heute noch häufig verwendete Programmiersprache, Cobol (common business oriented language, auf deutsch allgemeine wirtschaftsorientierte Sprache), entstand für diesen Zweck der kommerziellen Datenverarbeitung. Charakteristisch dafür sind die große Datenmenge und relativ wenige Rechenoperationen, die damit ausgeführt werden. Diese Programme heißen ein- und ausgabeintensiv.
Im Sinne dieser Zweierteilung kann man von der Dualität des Programmierens sprechen: Zeit und Raum spielen dabei eine Rolle. Die Forderung nach Geschwindigkeit der Programme nimmt die Fähigkeit des Rechnens (etwa im Zentralprozessor) eines Computers in Anspruch, während die Forderung nach großen Datenmengen die Fähigkeit braucht, diese zu speichern. Dies geschieht außerhalb des Prozessors, etwa im internen oder externen Speicher (im Arbeitsspeicher und z.B. auf der Festplatte).
Diese Dualität spiegelt sich auch in der heutigen Programmiermethodik durch die Unterscheidung von Algorithmen und Daten wieder.
Schon zur Anfangszeit des Programmierens wurde offensichtlich, dass jedes Programm (Was ein Programm ist, wollen wir hier nicht definieren.) aus konstanten und variablen Teilen bestehen muss. Der konstante Teil wird vom Programmierer definiert und wird im Laufe der Lebenszeit des Programms nie wieder verändert; er ist für jede Ausführung (d.h. bei jeder Benutzung, bei jedem Programmlauf) des Programms gleich. Der variable Teil ist jedoch bei jedem Programmlauf anders. Es gibt Programme ohne variablen Teil, ihr Ablauf ist jedes Mal gleich. Zwei Beispiele dafür:
Sie sind nicht allzu nützlich, da sie nur eine einzige Aufgabe erfüllen können. Sinnvoller ist es, Programme zu schreiben, die in verschiedenen Situationen unterschiedlich ablaufen. Zwei Beispiele:
Diese Programme müssen variable Teile enthalten, z.B. um sich den Namen des Benutzers oder die Koeffizienten der Gleichung zu merken. Diese variablen Teile heißen Daten. Es gibt jedoch auch konstante Daten in einem Programm, z.B. der Text "Hallo" oder der Exponent 2 der Gleichung.
Die Daten stellen den passiven Teil eines Programms dar. Im Gegensatz dazu stehen die Anweisungen, die beschreiben, wie das Programm seine Aufgabe erledigen soll. Sie operieren über den Daten; sie bilden den aktiven Teil des Programms. Dieser Teil realisiert einen Algorithmus. Ein Algorithmus ist eine Vorschrift, welche Aktionen durchzuführen sind. Er wird aus einem (von den Daten abhängigen) Satz von Anweisungen konstruiert. Die Auswahl des geeigneten Anweisungssatzes und die Konstruktion des Algorithmus ist die eigentliche Aufgabe des Programmierers.
Früher hat man auch variable Algorithmen geschrieben, also solche, die sich selbst modifizieren können. Es wurde aber erkannt, dass dadurch Programme entstehen, deren Ausführung schwer zu verstehen ist. Die Wartung (Fehlerkorrektur und Modifikation nach Fertigstellung) solcher Programme ist sehr teuer, oft teurer als neue zu schreiben. Moderne Programmiersprachen erlauben deshalb keine solchen selbstmodifizierenden Algorithmen. Wir unterscheiden zwischen konstanten und variablen Algorithmen nicht danach, ob sie sich selbst während des Programmlaufs verändern, sondern ob sie auf konstanten oder variablen Daten operieren.
Algorithmen, die über keine variablen Daten operieren (also gar keine oder nur konstante Daten haben), liefern bei jeder Ausführung gleiche Ergebnisse. Sie heißen konstante Algorithmen. Die ersten beiden, die die obigen Aufgaben lösen, sind Beispiele hierfür.
Zusammenfassend ist unsere Begriffsbildung: Jedes Programm besteht aus einem aktiven und einem passiven Teil, aus Algorithmen und Daten. Es gibt variable und konstante Daten, je nach dem, ob sie während des Programmlaufs verändert werden oder nicht. Es gibt variable und konstante Algorithmen, je nach dem, ob sie bei jeder Ausführung gleich ablaufen oder nicht. Variable Algorithmen müssen über variablen Daten operieren.
Auch in der weiteren Entwicklung der Programmiertechnologie ist diese Zweiteilung zwischen Daten und Algorithmen geblieben: In den meisten Programmiersprachen der nachfolgenden Generationen wie Algol-60, PL/1, Pascal oder C ist die Trennung zwischen den aktiven und passiven Elementen eines Programms, zwischen Algorithmen und Daten stark vorhanden. Erst in der letzten Zeit setzt sich die Erkenntnis mehr und mehr durch, dass diese Aufteilung künstlich, nur von der Technologie (des sog. Van-Neumann-Rechners, der theoretischen Grundidee der heutigen Computer) bestimmt ist, nicht aber zum Wesen der Programmierung gehört.
Algorithmen und Daten werden also zunehmend zusammengeführt. Man spricht von "intelligenten Daten" die selber "wissen", wie sie manipuliert werden dürfen; der Zugriff auf sie ist nicht möglich, ohne dieses "Wissen" zu benutzen. Der Begriff abstrakter Datentyp entstand schon sehr früh; dieser führte zum Begriff der Klasse, dem zentralen Konzept des heutzutage so gut klingenden Begriffs vom objektorientierten Programmieren (abgekürzt OOP).
Objektorientiertes Programmieren ist das Schlagwort der Neunziger. Unter diesem Titel wird oft einiges verkauft, was höchstens durch das farbige Erscheinungsbild etwas mit OOP zu tun hat. Aber auch viele gut gemeinte OO-Programme sind weit davon entfernt, die Grundkonzeption des Objektorientierten Programmierens durchgängig und konsequent zu verwirklichen.
Die Ursache hierfür ist psychologischer Art. Die meisten Programmierer, die heute objektorientierte Software schreiben wollen, haben vor 10 Jahren in Basic oder C das Programmieren gelernt. Ihre Denkweise (ihr Paradigma) ist prozedural. Sie haben vielleicht die Möglichkeiten, die in der OOP stecken, erkannt, werden aber von ihrer Prägung doch nicht frei. Immer wieder schleichen sich in die ansonsten vielleicht schön aufgebaute Klassenstruktur altmodische Ideen hinein, um doch noch ein Paar Bytes oder einige Schleifenschritte einzusparen. Oder, wenn das OO-Programm - bekanntlich - zu langsam ist, versucht man nicht durch einen schnelleren Prozessor sondern durch Tuning (durch Veränderungen in der Programmstruktur) die Antwortzeiten zu verbessern. Die Folge ist die Softwarekrise, die wirtschaftliche Not vieler Softwarehersteller, die die steigenden Kosten nicht in den Griff bekommen können.
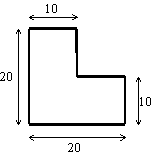
Diese Ansicht wird durch folgendes Logikrätsel belegt.
1. Aufgabe (Aufgaben aus diesem Lehrbuch sollen auf Papier, die Übungen jedoch am Rechner gelöst werden): Ein Bauer, der ein L-förmiges Feld besitzt, verstirbt. In seinem Testament hinterlässt er, dass es unter seinen vier Söhnen aufgeteilt werden soll, und zwar gleichförmig: Jeder Sohn soll eine Fläche gleicher Größe und gleicher Gestalt (ähnlich dem Originalfeld) erhalten. Die Aufgabe ist, das folgende Feld auf diese Weise in 4 gleichförmige Stücke aufzuteilen:
STOP! Nicht weiterlesen. Es wird dringend empfohlen, die 1. Aufgabe vollständig zu lösen (oder zumindest ihre Lösung auf der Begleitdiskette zu untersuchen), bevor die Nächste in Angriff genommen wird.
2. Aufgabe: Später stirbt der Nachbar des obigen Bauern. Er hat fünf Söhne und ein quadratisches Feld. Seine Abbildung befindet sich auf der nächsten Seite.
Er hinterlässt genauso ein Testament. Wie wird sein Feld aufgeteilt?
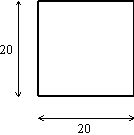
Die meisten Leser werden über die 2. Aufgabe deutlich länger nachdenken müssen, bis sie die relativ einfache Lösung finden, als wenn sie an der 1. Aufgabe nicht gearbeitet hätten: Die komplexen Konzepte hindern sie, einfache zu entwickeln.
Die Lehre, die aus der Arbeit an diesen beiden Übungen gezogen werden kann, ist folgende: Die Prägung durch die in der Vergangenheit gelösten Probleme bestimmt die Denkweise (das Paradigma) des Menschen. Sie ist ein Hemmnis, andersartig zu denken und dadurch Problemlösungen auf anderen Wegen zu suchen, sich ein neues Paradigma anzueignen. Nur durch einen bewusster Verzicht auf das Gekonnte wird der Weg zu neuartigen Lösungen frei gemacht. Ein Paradigmawechsel (z.B. durch die Sprachen APL, LISP, Prolog, SQL) ist in der Geschichte der Informatik bereits mehrfach angegangen worden. Obwohl es offensichtlich ist, dass unser traditionelles Programmierparadigma schon veraltet ist, wird heute immer noch überwiegend damit gearbeitet.
Die Absicht in diesem Lehrbuch für Object Pascal ist, die Technologie des Programmierens auf eine neue Basis der Wiederverwendbarkeit zu legen. Konventionelle Programmierkurse stützen sich alle auf eine bestimmte Sprache und fangen mit den einfachsten Sprachelementen (Zeichenvorrat, Namen und Bezeichner, Sprachelemente, usw.) den Unterricht an. Die Programmierkenntnisse werden "von unten" aufgebaut. Als Ergebnis entsteht ein sprachbasiertes Programmierparadigma: Man nimmt die primitiven Elemente der Sprache und konstruiert daraus Schicht für Schicht sein Programm. Die Folge davon ist, dass ein Durchschnittsprogrammierer jährlich ca. 500 Wiederholungen schreibt und sich jedes Mal Gedanken über ihre Korrektheit machen muss. Es gibt aber nur ca. 5-6 verschiedene Schleifenarten, alle anderen sind im Wesentlichen gleichartig. Sehr ähnliche bis gleiche Algorithmen werden immer wieder programmiert und jede Neuprogrammierung bedeutet neben Unwirtschaftlichkeit auch weitere Fehlerquellen. Auch wenn der Begriff Wiederverwendbarkeit mehr und mehr ins Gespräch kommt, werden die Bemühungen durch die Prägung überschattet, die aus der konventionellen pädagogischen Idee des Programmierunterrichts stammt.
Im vorliegenden Lehrbuch wird ein entgegengesetztes Konzept vorgestellt: die Programmierung "von oben". Statt mit sprachspezifischen Elementen anzufangen, werden dem Programmierlehrling Bausteine zur Verfügung gestellt, aus denen er seine ersten Erfolgserlebnisse zusammenbasteln kann. Der Vorteil dieser Vorgehensweise des wiederverwendbaren Programmierens ist langfristig offensichtlich: Das Rad muss nicht immer wieder erfunden werden. Die Hemmschwelle dazu besteht darin, dass neu zu programmieren einem oft einfacher erscheint als nach Vorhandenem zu suchen. Es wird dabei der Aufwand für die Fehlersuche in den neuen Programmen übersehen. Die zweite Schwierigkeit ist der Zusatzaufwand beim Archivieren, beim Dokumentieren der erstellten Bausteine für die Zukunft auf eine Art und Weise, dass sie leicht zu finden und zu verstehen sind.
Was ist nun ein Programm?
Alle technischen Geräte müssen durch den Menschen gesteuert werden, um ihre Aufgaben zu erledigen. Es kann keine echten Automaten (auf altgriechisch bedeutet: Selbstlernender) geben, die völlig selbstständig ihre Aufgaben entdecken und die Lösungswege selber finden. Der Hersteller des Geräts muss dieses selbst definierten und in das Gerät einprogrammieren.
Sei es eine Taschenlampe, ein Zigarettenautomat oder ein Flugzeug, jeder Apparat ist fähig, auf bestimmte Anweisungen hin (z.B. Schalter umkippen oder Knopf drücken) bestimmte Aktionen durchzuführen (etwa: zu leuchten oder ein Fünfmarkstück zurückzugeben). Diese Fähigkeit wurde in den Apparat eingebaut (auf einer Maschinensprache) und wird durch ein von außen kommendes Signal des Bedieners aktiviert. Dabei kann es sich auch um eine Reihe von Signalen handeln, etwa mehrere Knöpfe müssen in einer bestimmten Reihenfolge gedrückt werden. Einfachere Telefonapparate oder Fernbedienungen haben für jede Funktion genau eine Taste, während kompliziertere mehrfach belegte Tasten haben. Welche Funktion durch den Tastendruck aktiviert wird, hängt von den vorher gedrückten Tasten ab.
Bei manchen Fernbedienungen kann der Käufer durch Programmieren festlegen, durch welche Taste welche Funktion ausgelöst wird. Um die Funktion des Programmierens auszulösen, gibt es entsprechende Tasten.
Ähnlich sind auch Rechenanlagen (Computer) gebaut. Sie besitzen bestimmte Fähigkeiten (wenn auch zahlreicher als ein Zigarettenautomat), die durch eine Signalreihe von außen (etwa Tastatureingaben) aktiviert werden. Welche Tastatureingaben (Befehle) welche Funktion auslösen, muss man (ähnlich wie bei einem Telefonapparat) in der Bedienungsanleitung nachlesen.
Bei einer Fernbedienung wird durch das Programm meistens nur eine einzige Funktion einer Taste zugeordnet. Beim Rechner ist es jedoch möglich, einem Befehl eine ganze Reihe von Funktionen zuzuordnen. Diese Reihe besteht aus einzelnen Schritten, jeder Schritt ist eine elementare Fähigkeit, die dem Rechner von seinem Konstrukteur verliehen wurde. Diese heißen Maschinenbefehle oder Maschinenanweisungen. Ein Programm ist also eine Sequenz von Maschinenanweisungen. Diese Sequenz liegt in Form von elektronischen und magnetischen Signalen vor; sie kann vom Rechner direkt gelesen und ausgeführt werden. Man spricht von Maschinensprache. Sie ist zwar sehr einfach, da sie nur aus Nullen und Einsen besteht, ist jedoch für den Menschen sehr schwer handhabbar. Auch wenn die allerersten Rechner noch in Maschinensprache durch Knopfdrücke programmiert werden mussten, gibt es heute schon bequemere Wege dafür.
Das Bequemste wäre, einen Computer durch Spracheingabe zu steuern. Unsere Technik ist aber noch nicht so weit, auch wenn gute Hoffnung für die Zukunft besteht, dass die gesprochene (vielleicht eingeschränkte) Sprache vom Computer verstanden wird.
Um einen Rechner aber heute schon leichter programmieren zu können, wurden Programmiersprachen entwickelt. Diese sind geeignet, eine Sequenz von Schritten auf eine für den Menschen verständlichere Weise auszudrücken, die jedoch auch vom Rechner verstanden und ausgeführt werden kann. Die Entwicklung von Programmiersprachen ist mit der Entwicklung der Rechnertechnologie verknüpft: Je billiger, je leistungsfähiger die Rechner geworden sind, desto umfangreicher wurden die Programme, desto schwerer wurde es für den Menschen, sie zu verstehen. Modernere Programmiersprachen ermöglichen, verständlichere Programme mit weniger Aufwand zu erstellen.
Wir verstehen unter einem Algorithmus die Beschreibung einer Vorgehensweise in abstrakter Form, während ein Programm einen Algorithmus in einer Programmiersprache formuliert.
Programmieren ist Kommunikation: Der Mensch vermittelt dem Rechner, was er zu tun hat. Ein Werkzeug der Kommunikation ist die Sprache. Sie ist ursprünglich entstanden, um die Kommunikation zwischen zwei Menschen zu erleichtern. Diese sind die natürlichen Sprachen. Ein ähnliches Werkzeug wurde entwickelt, um die Kommunikation von Mensch zu Maschine zu erleichtern, die Programmiersprachen.
Im Laufe der letzten fünfzig Jahre entstanden unzählige Programmiersprachen. Einige von ihnen sind mehr verbreitet als andere. Manche sind für Spezialaufgaben (Robotersteuerung, Druckereibetrieb u.ä.) entwickelt worden, andere sind generell einsetzbar; diese sind Universalsprachen. Sie sind einander teilweise ähnlich, zeigen aber auch deutliche Unterschiede auf.
Hier folgt eine Übersicht zur Geneologie (auf deutsch: Stammbaum) der - nach Meinung des Autors - wichtigsten Programmiersprachen:
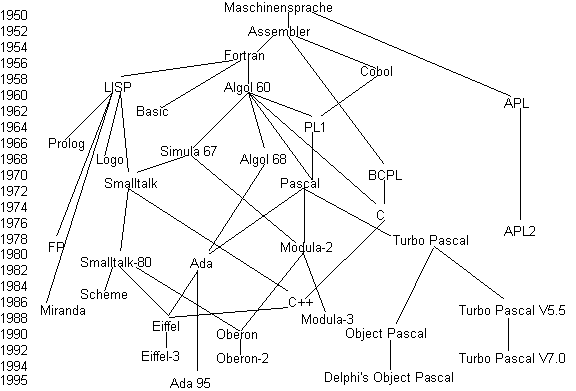
Die wesentlichen Konzeptsprünge in diesem Stammbaum sind:
Moderne Programme sind sehr komplex. Schon relativ einfach erscheinende Aufgaben wie die Darstellung eines Zeichens am Bildschirm oder die Bearbeitung eines Tastendrucks beinhalten die Ausführung von einigen Hundert Maschinenanweisungen. Ein komplexes Textverarbeitungsprogramm aus Maschinenanweisungen kann von keinem Menschen gelesen und verstanden werden. Müsste man bei der Lösung jeder Aufgabe den ganzen Prozess immer vor Augen haben, würde man sehr schnell den Überblick verlieren.
Um den Durchblick zu erleichtern, werden Programme schichtweise angeordnet. Eine solche Schicht ist z.B. die Hardware, die Maschine, die in der Lage ist, die einzelnen Anweisungen der Maschinensprache auszuführen. Weil die einzelnen Maschinenanweisungen nur sehr einfache Operationen sind, können auf dieser Schicht nur relativ einfache Programme gebaut werden, ohne dass sie unüberschaubar groß werden.
Viele Anweisungsfolgen (wie z.B. das Schreiben eines Zeichens auf den Bildschirm) treten jedoch wiederholt auf. Es erschien sinnvoll, diese zusammenzufassen und über der Hardware-Schicht eine höhere zu entwickeln: das Betriebssystem. Hinter einer einzigen Anweisung an das Betriebssystem verbergen sich komplexe Vorgänge auf der Maschinenebene, um die sich der Programmierer nicht zu kümmern braucht.
Auf Betriebssystemebene zu programmieren (etwa auf einer Assemblersprache - assemble auf deutsch: einsammeln oder zusammenfügen; Maschinenbefehle werden vom Assembler "eingesammelt" bzw. "zusammengefügt") ist jedoch immer noch recht kompliziert. Es wurde eine weitere Schicht entwickelt, die Sprachebene von höheren Programmiersprachen, wie auch Pascal. Eine einzige Anweisung auf der Sprachebene kann komplexe Vorgänge auf der Betriebssystemebene auslösen. Der Bediener des fertigen Programms kennt die Anweisungen auch nicht, die auf seine Tastendrucke hin ausgeführt werden.
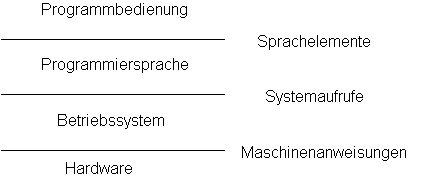
Die Erfahrung hat jedoch gezeigt, dass die Komplexität von heutigen Programmen auch auf der Sprachebene nicht beherrscht werden kann. Es wurde notwendig, weitere (diesmal eine unbegrenzte Anzahl von) Schichten einzuführen. Dies ist durch die modulare Struktur von Programmsystemen möglich. Hinter einer einzigen Anweisung an ein Modul verbergen sich typischerweise komplexe Vorgänge auf darunter liegenden Ebenen. Ebenso, wie der Assemblerprogrammierer nicht genau wissen muss, welche Maschinenanweisungen seine Betriebssystemaufrufe auslösen, kümmert sich der Benutzer eines Moduls auch nicht um die Details dieser Anweisung. Er muss nur die genauen Vorschriften kennen, wie er die gewünschte Wirkung erzielen kann. Diese werden in der Schnittstelle des Moduls angegeben. Seine Implementierung, d.h. die Art und Weise, wie diese Wirkung erzielt wird, bleibt dem Benutzer verborgen. Hierdurch wird das Geheimnisprinzip verwirklicht.
Dieses Schichtenmodell kann allerdings nicht nur oberhalb der Hardware-Ebene, sondern auch darunter ausgebaut werden. Die einzelnen Maschinenanweisungen lösen nämlich elektronische Operationen aus; der Hardware-Programmierer kennt sie nicht, er verlässt sich dabei auf den Elektroniker: Er hat diese aus Kabeln, Widerständen, Kondensatoren und Röhren, später aus Transistoren, heute aus IC's, Halbleitern und anderen Bauteilen zusammengebaut. Er kennt deren Funktionalität, über ihre physikalischen Eigenschaften muss er nicht viel wissen: Der Physiker kümmert sich darum. Hinter den elektronischen Eigenschaften der Materie verbergen sich mikrophysikalische Eigenschaften, die Gesetze der Physik operieren auf den Bausteinen der Chemie, die wiederum aus Elementarteilchen bestehen; und so weiter, bis in die unbekannten Tiefen der Materie. Das Prinzip ist überall dasselbe: Jede Ebene hat Internas und eine Schnittstelle, die von oben sichtbar ist. Auf diese können weitere, komplexere Funktionalitäten und somit eine neue Ebene aufgebaut werden.
Dieses Modell ist eine der wichtigsten Erkenntnisse des Software Engineering (auf deutsch etwa: Softwareentwicklungstechnologie, s. Kapitel 14.).
Programmieren besteht - wie jede konstruktive Tätigkeit - aus dem Zusammenfügen von vorhandenen Bausteinen mit Hilfe von vorhandenen Werkzeugen. Die Bausteine und die Werkzeuge bestehen aus anderen, einfacheren Bausteinen und wurden auch mit anderen, einfacheren Werkzeugen gebaut. Selbst der Urmensch hat seine erste Axt aus dem im Wald gefundenen Steinen und Knochen mit Hilfe von bearbeiteten Holzstücken angefertigt. So findet der Programmierer (auch der Anfänger) einige Werkzeuge (z.B. die Programmiersprache, der Übersetzer, der Editor) vor, mit deren Hilfe er aus den ihm zur Verfügung stehenden Bausteinen (Befehlen, Standardbibliotheken, Prozeduren, usw.) sein Programm zusammenstellt.
Dieser Prozess hat zwei wesentliche Phasen: die Erfassung des Programms (d.h. die Formulierung der Gedanken des Programmierers, wie die Aufgabe gelöst werden sollte, auf eine im Computer speicherbare Weise) und die Ausführung des Programms (das eigentliche Ziel des Programmierers). Bei den meisten heutigen Programmiersystemen (wie auch in Pascal) werden diese beiden Grundschritte durch weitere, technisch bedingte Zwischenschritte ergänzt. Dies kann vereinfacht folgendermaßen dargestellt werden:
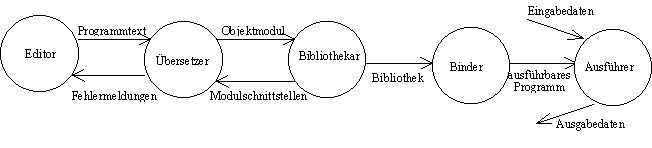 Die dargestellte Vorgehensweise ist
charakteristisch für die heute gängigen Programmiersprachen und ihre Übersetzer. Es
sind auch andere Wege vorstellbar, wie ein ausführbares Programm entsteht. Die
Ausführung des Programms ist jedoch unabhängig vom Weg, wie es entstanden ist.
Die dargestellte Vorgehensweise ist
charakteristisch für die heute gängigen Programmiersprachen und ihre Übersetzer. Es
sind auch andere Wege vorstellbar, wie ein ausführbares Programm entsteht. Die
Ausführung des Programms ist jedoch unabhängig vom Weg, wie es entstanden ist.
Jetzt wollen wir uns den einzelnen Werkzeugen der Programmentwicklung zuwenden.
Programme werden üblicherweise in einer für Menschen verständlichen und erlernbaren Sprache formuliert. Sie werden (zurzeit noch meistens) textuell (es gibt Bemühungen, Programme grafisch zu formulieren; in bestimmten Teilbereichen ist dies schon möglich) dargestellt. Der Programmierer verbalisiert seine Gedanken mit Hilfe eines Editors (auf deutsch: Textredakteur). Dies kann ein selbständiger, teurer Editor sein, der für das Erfassen von beliebigen Texten geeignet ist, oder aber ein einfacheres, mit dem Betriebssystem ausgeliefertes Schreibprogramm (Edit, Editor, vi oder gar Edlin). Für die Programmentwicklung ist es am besten, wenn die Entwicklungsumgebung des Compilers einen integrierten Editor hat, aus dem heraus die Übersetzung direkt aufgerufen werden kann. Im Falle eines Fehlers, den der Übersetzer entdeckt, wird die Schreibmarke (auf englisch: cursor) des Editors dann direkt auf die fehlerhafte Stelle positioniert. Der Programmierer korrigiert dann sein Programm (möglichst alle entdeckten Fehler) und versucht es mit einem neuen Übersetzergang, ohne den Editor verlassen zu müssen.
Das Ergebnis des Programmierens, das Quellprogramm (auf englisch: source code) wird üblicherweise in einer Textdatei gespeichert, damit es nicht bei jeder Sitzung neu eingetippt werden muss. Ein Programm entsteht also als eine Folge von (druck- und lesbaren) Zeichen (Buchstaben, Ziffern und Sonderzeichen).
Das zentrale Werkzeug für die Programmentwicklung ist der Compiler (auf deutsch: Übersetzer; compile auf deutsch: zusammenstellen). Er übersetzt den für menschliche Augen lesbaren Text, das Quellprogramm, in eine für Menschen kaum lesbare Sprache, in die Maschinensprache. Der Compiler verarbeitet die Textdatei. Er versucht dabei, die Gedanken des Programmierers (natürlich nur mechanisch) nachzuvollziehen, d.h. das Programm "zu verstehen", und in Maschinensprache zu übersetzen. Deswegen heißt der Compiler oft auch Übersetzer. Er kann dabei manche Fehler entdecken. Wenn dies geschieht, dann muss das Programm mit dem Editor korrigiert werden, bis der Compiler fehlerfrei durchläuft.
Die kleinste Menge von Text, die vom Compiler in einem Gang erfolgreich verarbeitet werden kann, heißt Übersetzungseinheit. Eine Programmdatei kann mehrere Übersetzungseinheiten enthalten; diese werden nacheinander übersetzt. Manche Compiler ermöglichen aber auch, dass eine Übersetzungseinheit aus mehreren Dateien zusammengestellt wird: So weist z.B. ein sog. Einschlussbefehl (oft include-Befehl genannt) den Compiler an, an dieser Stelle den Text aus einer anderen Datei (aus der include-Datei) einzufügen.
Einige Programmentwicklungsumgebungen enthalten auch einen Interpreter, der ein Programm ohne einen zusätzlichen Übersetzungsgang ausführt. Diese werden meistens in der Entwicklungsphase benutzt, da die Ausführungsgeschwindigkeit des Interpreters deutlich unter der eines übersetzten Programms liegt. Für die Sprache Pascal spielt diese Methode selten eine Rolle.
Das Ergebnis der Übersetzung heißt Objektcode, oft in Form eines Bindemoduls, oder Objektmoduls. Dies ist genau das Abbild des zu entwickelnden Programms auf Maschinensprache, wie die Übersetzungseinheit es auf der Programmiersprache darstellt. Einige Compiler (wie auch viele Pascal-Compiler) schreiben es in eine eigene Datei, in eine Objektdatei; andere stellen aus den Bindemodulen Bibliotheken zusammen. Die meisten Pascal-Entwicklungssysteme verwirklichen die Kombination beider Methoden mit Hilfe eines Bibliotheksverwalters: Er fügt vorhandene Objektdateien zu einer Bibliothek zusammen.
Das Bindemodul stellt noch kein fertiges Programm dar, da es nur jene Teile enthält, die in der entsprechenden Übersetzungseinheit enthalten sind. Die meisten Programme bestehen aus mehreren Modulen, die möglicherweise in mehreren Übersetzungseinheiten ausformuliert worden sind. Darüber hinaus nehmen selbst die einfacheren Programme Dienste von anderen, vielleicht von mit dem Compiler oder mit diesem Lehrbuch ausgelieferten Modulen in Anspruch. Das heißt, Bausteine werden benötigt, die im Quellprogramm nur benutzt aber nicht definiert (wie es heißt, importiert) worden sind. Die Texte dieser Module müssen - wenn nicht schon geschehen - ebenfalls übersetzt werden und als Bindemodul vorliegen, damit der Binder (oder Linker, nach dem englischen Ausdruck linkage editor, auf deutsch: Verbinder-Redakteur) sie zu einem lauffähigen Programm oder Zielprogramm zusammenbinden kann. Dieses Programm liegt auch in Maschinencode vor und wird fast immer in einer eigenen Datei, einer ausführbaren Datei (z.B. in DOS exe-Datei; seltener in einer Bibliothek) abgelegt. Dies kann bei Bedarf mit Hilfe des Laders in den Speicher des Rechners geladen und dann ausgeführt werden.
Nachdem ein Programm erfasst und verschiedenartig bearbeitet (z.B. übersetzt und gebunden) wurde, kann es ausgeführt werden. Der Ausführer ist ein abstraktes Gebilde, das genau das tut, was im Programm für ihn bestimmt wurde. Der Ausführer kann der Prozessor eines Computers sein, der das vom Compiler übersetzte Programm ausführt, oder ein fleißiger Student mit Papier und Bleistift, der Schritt für Schritt genau das nachvollzieht, was im Programm steht. Der Interpreter, die Alternative zum Übersetzer, kann ebenfalls die Rolle des Ausführers übernehmen. Welche Bestandteile des Programms welche Aktionen beim Ausführer bewirken, gehört zur Semantik (s. Kapitel 1.8.3) der Programmiersprache. Ihr Verständnis gehört zur Kenntnis der Sprache.
Manche Compilersysteme erstellen immer ein selbstständig lauffähiges Programm. Oft sind diese aber sehr groß, da sie alle Funktionalitäten enthalten. Um ihre Größe zu reduzieren, wird manchmal nicht alles in das Programm eingebunden, sondern es wird vorausgesetzt, dass beim Ausführen des Programms das Laufzeitsystem vorhanden ist. Dies ist häufig der Fall z.B. bei Fehlerbehandlung: Kann ein Programm nicht ordnungsgemäß zu Ende laufen, werden Fehlerbehandlungsroutinen nachgeladen, um die Art des Fehlers dem Bediener des Programms zu melden, und evtl. um weitere Anweisungen abzufragen.
Das Betriebssystem kann aus der Sicht des Programmierers als ein Teil des Laufzeitsystems betrachtet werden, da es auch bei der Ausführung des Programms verschiedene Dienste übernimmt.
Oft ist die Grenze zwischen dem Programm und dem Laufzeitssystem nicht eindeutig zu ziehen: Manchmal werden Teile des Laufzeitssystems in die Programmdatei eingebunden; manchmal befinden sie sich in dynamischen Nachladebibliotheken (auf englisch: dynamic loading library, abgekürzt: DLL).
Bei der Ausführung eines Programms wird der Rechner (üblicherweise mit Hilfe des Betriebssystems) angewiesen, die im Programm enthaltenen einzelnen Anweisungen auszuführen. Dies ist das eigentliche Ziel des Programmierens: dem Rechner zu sagen, was er zu tun hat.
Die meisten Programme benötigen Eingabedaten und produzieren Ausgabedaten. Welche und wie sie verarbeitet werden, wird im Programmtext angegeben. Die Eingabedaten des Editors sind beispielsweise die Tastendrucke, seine Ausgabedaten sind die Textdatei. Diese wird vom Übersetzer als seine Eingabedaten gelesen, der seinerseits die Fehlermeldungen und evtl. das Bindemodul als Ausgabedaten schreibt. Der Binder (oder der Ausführer) liest dieses von hier heraus. Das Zielprogramm kann (muss aber nicht) ebenfalls Ein- und Ausgabedaten bearbeiten:

Die ersten drei Werkzeuge (der Editor, der Übersetzer und der Binder) reichen im Prinzip für die Produktion von Programmen auf einer höheren Programmiersprache. Viele Binder arbeiten aber auch noch mit der Bibliotheksverwaltung zusammen. Dies bedeutet, dass Bindemodule zusammengefasst in einer Bibliothek (meistens eine Datei, manchmal mit Hilfsdateien) abgelegt werden. Das erspart vor allem Speicherplatz. Der Binder liest sie von da heraus und erzeugt das ausführbare Programm. Das Ergebnis des Bindens kann aber auch ein weiteres Bindemodul sein und auch in die Bibliothek abgelegt werden.
Es ist möglich, dass gleichzeitig mehrere Bibliotheken benutzt werden, insbesondere wenn vorgefertigte Programmbausteine in Anspruch genommen werden. So kann ein Softwarehaus seine käuflichen Turbo-Pascal-Bausteine in Form von Bibliotheken zur Verfügung stellen; diese können mit der privaten Bibliothek des Benutzers und der Standardbibliothek (enthält viele, am häufigsten benutzte Bausteine) des Compilers zusammen benutzt werden. Dem Binder muss dabei mitgeteilt werden, wo sich diese Bibliotheken befinden. Dies kann im Rahmen der Projektverwaltung geschehen: Eine Projektdatei enthält alle Informationen, aus welchen Bibliotheken und Objektmodulen das Ergebnis zusammengebunden werden soll.
Wie dies konkret geschieht (z.B. ob durch ein Hilfsprogramm), muss aus der Bedienungsanleitung des Sprachsystems entnommen werden.
Meistens enthält das ausführbare Programm noch logische Fehler: Es tut nicht genau das, was sich der Programmierer vorgestellt hat. Er muss diese Fehler suchen. Einige Compiler stellen Werkzeuge für Ablaufverfolgung (auf englisch debugger, auf deutsch etwa: Entwürmer), für die Fehlersuche zur Verfügung, um zu sehen, was innerhalb des Programms geschieht. Der Programmierer kann mit ihrer Hilfe nachvollziehen, ob das Programm wirklich das tut, was er sich vorgestellt hat. Wenn dies nicht der Fall ist, muss er herausfinden, an welcher Stelle der Programmlauf von seinen Vorstellungen abweicht..
Der Programmierer soll sich aber nicht täuschen lassen, wenn sein Programm scheinbar richtig läuft. Viele Programme laufen in einigen Situationen (mit bestimmten Eingabedaten) richtig, in anderen falsch. Es gehört zum Prozess der Programmentwicklung, das Programm auszutesten. Leider gibt es hier keinen hundertprozentigen Weg; viele kommerziell käufliche Programme enthalten noch Fehler, weil sie nicht vollständig ausgetestet werden können. Durch das Testen soll nicht die Fehlerfreiheit eines Programm nachgewiesen, sondern möglichst viele vorhandene Fehler aufgespürt werden.
Nachdem ein Fehler entdeckt und (vielleicht mit Hilfe der Ablaufverfolgung) lokalisiert worden ist, muss das Quellprogramm korrigiert, das Programm neu übersetzt und gebunden werden, und alle Testläufe müssen wiederholt werden. Es ist durchaus möglich, dass durch die Korrektur des gefundenen Defekts ein neuer Fehler eingebaut worden ist.
Besonders schwierig ist es, Fehler zu finden, wenn sie sich nicht im eigenen Programmteil befinden, sondern aus einem importierten Baustein stammen. Deswegen ist es sehr wichtig, die Bausteine gut auszutesten. Andererseits darf die Korrektur eines Bausteins nicht dazu führen, dass alle Programme, die ihn importieren, verändert werden müssen. Hierzu werden besondere Techniken gebraucht: Die Schnittstelle des Bausteins soll unverändert bleiben, die Veränderungen müssen an seinem Interna durchgeführt werden. Moderne Programmentwicklungswerkzeuge und Programmiersprachen unterstützen die Modularisierung, um diese Trennung und die Unabhängigkeit der Bausteine voneinander zu verwirklichen.
Es ist die Erfahrung jedes Programmierers, dass bestimmte Aufgaben immer wieder mühsam erledigt werden müssen. Um diese Tätigkeit zu optimieren, werden oft Programmgeneratoren zur Verfügung gestellt, die bestimmte Arten von Programmen (meistens grafisch gesteuert) erzeugen. Hierzu gehören z.B. die Bildschirmobjektgeneratoren, die Bildschirmobjekte wie Menüs, Masken oder Schaltflächen produzieren. Aus einem grafisch dargestellten Datenmodell kann ein Datenbankgenerator Programmteile erzeugen, die die Datenhaltung übernehmen. Ein Testtreibergenerator erzeugt leistungsfähige Testtreiber für einzelne Module aus ihrer Schnittstellenbeschreibung.
Alle diese Werkzeuge werden mit den modernen Compilern im Rahmen einer Entwicklungsumgebung ausgeliefert, die mindestens diese drei Werkzeuge (Editor, Übersetzer und Binder) in ein menügesteuertes Programm integrieren. Neben der bequemen Bedienung ist deren großer Vorteil, dass die vom Compiler erkannten Fehlerstellen gleich lokalisiert und im Editor korrigiert werden können. Bessere Entwicklungsumgebungen schließen weitere Werkzeuge wie ein Ablaufverfolger , Projektverwaltung, usw. ein.
1. Übung: Lernen Sie Ihren Pascal-Compiler und seine Entwicklungsumgebung kennen. Schreiben Sie einen Brief an Ihre Oma mit Hilfe des Editors. Speichern Sie den Brief in einer Datei. Kopieren Sie anschließend die Programmdatei namens OMA.PAS von der Begleitdiskette auf Ihre Festplatte. Lesen Sie ihren Inhalt und korrigieren Sie ihn mit Hilfe Ihres Editors, indem Sie im Programmtext den Namen "Petruschka" auf Ihren eigenen austauschen. Übersetzen Sie das korrigierte Programm und binden Sie es. Führen Sie es zum Schluss aus und teilen Sie ihm den Dateinamen des Briefes an Ihre Oma mit. Dieser Brief stellt die Eingabedaten für das Programm dar. Die Ausgabedaten sehen Sie am Bildschirm.
Eine Programmiersprache ist ähnlich aufgebaut wie eine natürliche Sprache, nur viel einfacher. Es gibt einen festen Wortschatz: Diese heißen reservierte Wörter oder Schlüsselwörter (eine unglückliche Übersetzung des englischen key word) , die meistens aus dem Englischen stammen und sinngemäß zu benutzen sind: z.B. class oder while. In diesem Buch werden sie fett gedruckt. Für neue Begriffe kann man nach bestimmten Regeln neue Wörter, Bezeichner oder benutzerdefinierte Namen (z.B. alter oder telefonbucheintrag) erfinden. Reservierte Wörter können meistens nicht als Bezeichner benutzt werden.
Alle Wörter des Programms werden aus bestimmten Zeichen zusammengesetzt; in natürlichen Sprachen sind dies die Laute oder in Schriftform die Buchstaben; bei Programmiersprachen (bei denen die Texte ja immer in schriftlicher Form vorliegen) kommen zu den (kleinen und großen) Buchstaben die zehn Ziffern und ein Satz von Sonderzeichen (z.B. das Pluszeichen + oder die Unterstreichung _ ) dazu.
Im Gegensatz zu manchen Programmiersprachen wie C, sind in Pascal Klein- und Großbuchstaben austauschbar (außer in Zeichenketten; ein Relikt aus Zeiten der Lochkarten und -streifen mit nur Großbuchstaben). Die reservierten Wörter werden kleingeschrieben, (z.B. class oder while); die benutzerdefinierten können Klein- und Großschreibung gemischt benutzen; traditionell werden in den meisten Bezeichnern für Objekte und Unterprogramme Kleinbuchstaben benutzt (z.B. alter oder telefonbucheintrag), während Typen und Klassen gemischt (z.B. TBool oder CFarbe). Für die bessere Lesbarkeit sollen Unterstreichungen eingefügt werden: telefon_buch_eintrag. Eine Silbentrennung am Zeilenende, wie etwa tele-fonbucheintrag, ist verboten. Das Zeilenende ist ein Trennzeichen, genauso wie ein Leerzeichen (auf englisch: blank), ein Tabulatorzeichen und einige andere, die reservierte Wörter und benutzerdefinierte Bezeichner abschließen.
Es sind auch andere Konventionen möglich, z.B. alle Bezeichner groß zu schreiben. Nicht die Wahl der Konvention das Wichtige, sondern die Konsequenz, sie durchgehend einzuhalten. Die Empfehlung des Autors ist darüber hinaus, in Programmen, die nur im deutschsprachigen Raum gelesen werden, für selbst definierte Bezeichner deutsche Wörter zu benutzen. Dadurch ist auch eine Unterscheidung zu den aus importierten Bibliotheken stammenden Namen möglich.
Wie aus den reservierten Wörtern, Sonderzeichen und Bezeichnern sinnvolle Sätze (d.h. Programme) gebildet werden können, wird durch die Syntax der Sprache geregelt. Die Syntax besteht aus einem Satz von syntaktischen Regeln, meistens formal in einer Metasprache aufgezeichnet. Für die deutsche Sprache sind solche syntaktischen Regeln beispielsweise, dass das Prädikat im Aussagesatz an der zweiten Stelle steht, oder dass die Adjektive vor dem Substantiv stehen müssen (im Französischen können sie ja auch nach dem Substantiv stehen). In Pascal ist eine vergleichbare Regel, dass der Rumpf jeder Prozedur mit dem reservierten Wort BEGIN eingeleitet werden muss oder dass Anweisungen mit einem Strichpunkt ; (Semikolon) abgeschlossen werden müssen.
Die Metasprache, in der die Syntax formal beschrieben wird, ist - im Vergleich zur Sprache selbst - relativ einfach. Sie besteht aus Metazeichen, syntaktischen Begriffen (sie heißen auch nichtterminale Symbole oder Zwischensymbole) und Endsymbolen, d.h. Elementen der Programmiersprache (sie heißen auch terminale Symbole). Ein Beispiel für syntaktische Begriffe ist Ziffer, während 1, 3 und 0 Endsymbole sind; diese kommen in der Zielsprache (in der betrachteten Programmiersprache) als Sprachelemente vor.
Für jeden syntaktischen Begriff gibt es eine Regel, die beschreibt, welche Symbolfolgen für diesen Begriff eingesetzt werden können. Für den Begriff Ziffer sieht z.B. die Regel folgendermaßen aus:
Ziffer ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Hier sind das Zeichen | und die Zeichenfolge (obwohl sie aus drei Zeichen besteht, sagt man trotzdem Zeichen dafür) ::= die Metazeichen. | bezeichnet die Alternative und wird als "oder" gelesen. Das Metazeichen ::= heißt Definition und kann gelesen werden wie "wird definiert als" oder "wird ersetzt durch".
Eine syntaktische Ableitung besteht daraus, dass ausgehend von einem ursprünglichen Begriff alle Begriffe durch je eine ihren Regeln entsprechende Symbolfolge ersetzt werden, bis man keine syntaktischen Begriffe mehr in der Folge hat. Das Ergebnis besteht also nur aus Endsymbolen und stellt einen syntaktisch gültigen Programmausschnitt dar, der dem ursprünglichen Begriff entspricht.
Im Regelsatz für die Bildung von einfachen Bezeichnern (in Turbo Pascal ist dieser Regelsatz etwas komplexer) werden die weiteren Metazeichen { und } verwendet, sie definieren die Wiederholung; der Inhalt zwischen den zwei geschweiften Klammern kann beliebig oft (null-mal, einmal, zweimal, usw.) wiederholt werden.
Bezeichner ::= Buchstabe { Buchstabe_oder_Ziffer }
Buchstabe_oder_Ziffer ::= Buchstabe | Ziffer
Buchstabe ::= Kleinbuchstabe | Großbuchstabe
Kleinbuchstabe ::= a | b | c | d | e | f | g | h | i | j | k | l | m |
n | o | p | q | r | s | t | u | v | w | x | y | z
Großbuchstabe ::= A | B | C | D | E | F | G | H | I | J | K | L | M |
N | O | P | Q | R | S | T | U | V | W | X | Y | Z
Ziffer ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Hier sind Bezeichner, Buchstabe_oder_Ziffer, Buchstabe, Kleinbuchstabe, Großbuchstabe und Ziffer sechs syntaktische Begriffe, die zweimal 26 Buchstaben und 10 Ziffern die Endsymbole. Wir werden diese fett drucken, um sie von den Zwischensymbolen zu unterscheiden.
Die erste Regel besagt, dass ein Bezeichner mit einem Buchstaben anfangen muss, worauf eine beliebige Anzahl von Buchstabe_oder_Ziffern folgen kann (möglicherweise keines). Nach der zweiten Regel ist Buchstabe_oder_Ziffer entweder ein Buchstabe oder eine Ziffer; die nächste Regel definiert, dass ein Buchstabe ein Kleinbuchstabe oder ein Großbuchstabe sein kann. Was ein Kleinbuchstabe, ein Großbuchstabe und eine Ziffer ist, beschreiben die letzten drei Regeln.
Für das Beispiel einer syntaktischen Ableitung wird untersucht, ob die Zeichenfolge Var1 aus dem Begriff Bezeichner abgeleitet werden kann:
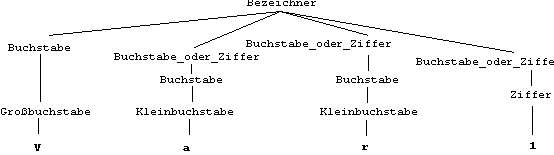
Hier wird zuerst Bezeichner seiner Regel entsprechend durch die Folge Buchstabe Buchstabe_oder_Ziffer Buchstabe_oder_Ziffer Buchstabe_oder_Ziffer (die durch die geschweiften Klammern dargestellte Wiederholung wurde dreimal genommen) ersetzt. Anschließend wurde die erste Buchstabe_oder_Ziffer durch Buchstabe, die zweite durch Buchstabe und die dritte durch Ziffer ersetzt. Im nächsten Schritt wurden die drei Vorkommnisse von Buchstabe jeweils durch Großbuchstabe, Kleinbuchstabe und Kleinbuchstabe ersetzt, schließlich wurden alle vier syntaktischen Begriffe durch Endsymbole (Zeichen der Programmiersprache) ersetzt. Das Ergebnis ist, dass Var1 ein syntaktisch gültiger Bezeichner ist.
Generell kann man aus den obigen Regeln herauslesen, dass jeder Bezeichner mit einem (kleinen oder großen) Buchstaben anfangen muss, auf den eine beliebige Anzahl von Buchstaben und Ziffern folgen kann. Es ist auch ersichtlich, dass deutsche Umlaute in Bezeichnern nicht akzeptiert werden.
Pascal-Bezeichner können zusätzlich das Zeichen Unterstreichung enthalten. Sie können theoretisch beliebig lang sein, praktisch begrenzen aber Compiler ihre Länge.
In der Sprachdefinition befindet sich die Syntaxbeschreibung von Pascal in dieser Notation. Sie heißt nach ihren Entwicklern Backus-Naur-Form oder BNF-Syntax. Es gibt auch viele andere Wege, eine Syntax zu beschreiben, durch die eine Sprache genauer als in der BN-Form definiert werden kann.
Es gibt nämlich Quellprogramme, die der Syntax genau entsprechen, und trotzdem fehlerhaft sind. Zu den Regeln einer Sprache gehören nämlich auch noch die Kontextbedingungen, d.h. die Gesetze, die den Zusammenhang zwischen den einzelnen Sprachkonstruktionen beschreiben. Beispielsweise, wenn der an sich gültige Bezeichner Var1 an einer Stelle benutzt wurde, muss er an einer anderen Stelle vereinbart worden sein. Obwohl es möglich ist, die Kontextbedingungen auch formal zu definieren (Dies gehört zur wissenschaftlichen Definition einer Programmiersprache.), sind für den Alltagsbenutzer (und auch für manche Fachleute) solche Syntaxbeschreibungen unbrauchbar kompliziert. Deswegen werden diese zusätzlichen Regeln normalerweise in einer natürlichen Sprache (verbal) beschrieben.
Neben der Syntax gehört zur Beschreibung einer Sprache die Semantik (das altgriechische s h m a - séma - bedeutet Zeichen), die Bedeutung der einzelnen Sprachkonstruktionen. Sie definiert, wie der Ausführer handeln muss, wenn er ein Sprachelement im Programm entdeckt: Was geschieht, wenn man einen Bezeichner definiert? Was wird eine bestimmte Anweisung im laufenden Programm bewirken? Das Verständnis der Semantik ist eine Voraussetzung dafür, dass man sinnvolle Programme schreibt, die genau das tun, was der Programmierer sich im Voraus vorgestellt hat.
Die Semantik einiger Programmelemente ist von der Sprache her gegeben: Die reservierten Worte wie FOR oder USES können nur mit einer bestimmten Bedeutung (wie "Zählschleife" oder "Modul importieren") benutzt werden. Andere Programmelemente, insbesondere die Namen (wie z.B. ein Bezeichner - in C++ gibt es auch andere Namen), werden vom Programmierer mit einer Bedeutung versehen.
In diesem Sinne unterscheiden wir zwischen Vereinbarung (oft auch als Deklaration bezeichnet) und Definition eines Namens, auch wenn diese beiden oft zusammenfallen. Die Vereinbarung beschreibt die syntaktische Position eines Namens (z.B. die Anzahl und Typen der Parameter einer Prozedur), während die Definition (z.B. ihr Rumpf) die Semantik beschreibt (was die Prozedur eigentlich tut). Je mehr man von einem Namen auf seine Semantik assoziiert, desto lesbarer ist ein Programm. Dies wird erreicht, indem ein Name die Abstraktion seiner Bedeutung ist.
Bei der Erstellung eines Programms werden oft Fehler gemacht. Die oben genannten Werkzeuge können einige dieser Fehler finden.
Der Compiler findet die so genannten Syntaxfehler. Diese sind diejenigen, die der Definition der Sprache grob widersprechen. Sie entsprechen einem Grammatikfehler, z.B. ein fehlender Satzteil im Deutschen. Sie stammen oft aus Tippfehlern, aber auch oft aus der mangelnden Kenntnis der Sprache. Solche Art von Fehler ist z.B., wenn ein Wort falsch oder Wörter in falscher Reihenfolge geschrieben wurden. Ein Fehler ähnlicher Art ist, wenn ein benutztes Programmobjekt nicht definiert oder in falschem Zusammenhang benutzt wurde.
Der Compiler kann auch manche Denkfehler entdecken, wenn z.B. Äpfel mit Birnen addiert werden sollen. Diese heißen Typfehler. Es gibt auch noch weitere Fehlerarten, die der Compiler auffängt. Findet er jedoch keine Fehler mehr in einem Programm, bedeutet dies noch bei weitem keine Fehlerfreiheit. Der Binder kann weitere Fehler identifizieren, z.B. wenn ein benutzter fremder Programmbaustein nicht gefunden oder falsch eingebunden wurde.
Ein Laufzeitfehler kann von einem fehlerfrei übersetzten und gebundenen Programm verursacht werden, wenn das Laufzeitsystem eine fehlerhafte Situation (z.B. unerlaubten Wert) wahrnimmt. Über geeignete Meldungen und Ausnahmebehandlung kann die Ursache dafür ermittelt werden.
Die problematischste Art von Fehlern sind jedoch die logischen Fehler. Diese werden erst entdeckt, wenn das fertig gebundene, laufende Programm beim Ausprobieren nicht immer das tut, was es sollte. Um logische Fehler zu finden, muss das Programm getestet werden. Tests können jedoch im Allgemeinen die Fehlerfreiheit nicht beweisen, sie können nur einige (leider nicht alle) Fehler entdecken. Nach dem Aufdecken von Fehlern müssen sie lokalisiert werden, d.h. ihre Ursache muss gefunden und beseitigt werden. Oft ist dies eine dem Auffinden von Fehlern ähnlich schwierige Aufgabe.
| © APSIS GmbH |